multidms usage examples¶
This page documents and demonstrates, in detail, the various package interfaces when using multidms package, including: 1. Data class 2. Model class 3. fit_model & fit_models utilities 4. ModelCollection class
Note:
Here, we use data from deep mutational scanning experiments across 3 different homologs of the SARS-CoV-2 Spike protein. This analysis is only run on a subset of this data for the purpose of this example. For the full analysis run in our manuscript, see the manuscript analysis page at https://matsengrp.github.io/SARS-CoV-2_spike_multidms/.
[1]:
import pickle
import warnings
import pandas as pd
import matplotlib.pyplot as plt
import numpy as onp
import multidms
[2]:
# %matplotlib inline
# warnings.simplefilter('ignore')
Data class¶
In order to fit a model, we first need to prep our training data in the form of a multidms.Data object. We keep the static data object separate from the model objects so that multiple multidms.Model objects may efficiently share references to the same fitting data, thus minimizing the memory and computations required to prep and store the data. A full description of the options for data prep and the resulting object attributes are available via the API documentation, or directly from the
python docstring directly via
help(multidms.Data)
You can initialize a Data object with a pd.DataFrame where each row is sampled variant with the following required columns:
condition - Experimental condition from which a sample measurement was obtained.
aa_substitutions - Defines each variant \(v\) as a string of substitutions (e.g., ‘M3A K5G’). Note that while conditions may have differing wild types at a given site, the sites between conditions should reference the same site when alignment is performed between condition wild types. Finally, be sure wildtype variants have an empty string in this column
func_score - The functional score computed from experimental measurements.
[3]:
func_score_df = pd.read_csv("func_score_df_delta_BA1_10K.csv").fillna("")
func_score_df
[3]:
| func_score | aa_substitutions | condition | |
|---|---|---|---|
| 0 | -0.9770 | T29S V622M D1199Y | Delta-2 |
| 1 | -0.1607 | N87K A846S K947R T1117R L1203F | Delta-2 |
| 2 | -3.5000 | S46T Q506- A845R A879V N1192D | Delta-2 |
| 3 | -1.9102 | L10P V327F I1179V | Delta-2 |
| 4 | 1.0093 | Q474H S686- | Delta-2 |
| ... | ... | ... | ... |
| 9995 | 0.8023 | Omicron_BA1-2 | |
| 9996 | 0.3779 | Omicron_BA1-2 | |
| 9997 | -0.9409 | V1176S | Omicron_BA1-2 |
| 9998 | 0.1793 | A484L H1088Y | Omicron_BA1-2 |
| 9999 | -0.9141 | N450D P479T | Omicron_BA1-2 |
10000 rows × 3 columns
Note that here we have multiple measurements for identical variants from individual barcode replicates
[4]:
func_score_df.aa_substitutions.value_counts()
[4]:
aa_substitutions
1567
D142S 7
P26L 7
T76I 6
L368I 6
...
E702V V736M 1
A1080V 1
D178R P621R D796S 1
F329S K854N K1191T 1
N450D P479T 1
Name: count, Length: 7637, dtype: int64
Next, we’ll initialize the dataset using ‘Delta-2’ as the reference condition. Upon instantiation the object performs the data preparation which can be summarized as:
Optionally, aggregating identical variants grouped by aa string and condition.
Inferring the site map each condition, so as to identify the wildtype of the reference and non-identical sites for each non-reference condition.
Converting substitution string of non-reference condition variants to be with respect to a reference wildtype (if necessary). See the docstring for a more in-depth description and a toy example
Setting helpful static attributes with helpful summaries of the data. We’ll take a look at a few notable attributes below.
initializing the raw training data as binarymap objects. Each condition will be associated with it’s own
binarymapwhich all share the same allowed_subs.
[5]:
data = multidms.Data(
func_score_df,
alphabet = multidms.AAS_WITHSTOP_WITHGAP, # AAS, AA_WITHSTOP, AA_WITHGAP, or AA_WITHSTOP_WITHGAP
collapse_identical_variants = "mean", # False, "median"
reference = "Delta-2", # any condition
verbose = True, # progress bars
nb_workers=4 # threads
)
inferring site map for Delta-2
inferring site map for Omicron_BA1-2
INFO: Pandarallel will run on 4 workers.
INFO: Pandarallel will use Memory file system to transfer data between the main process and workers.
/home/jgallowa/mambaforge/envs/multidms-dev/lib/python3.11/multiprocessing/popen_fork.py:66: RuntimeWarning: os.fork() was called. os.fork() is incompatible with multithreaded code, and JAX is multithreaded, so this will likely lead to a deadlock.
self.pid = os.fork()
unknown cond wildtype at sites: [1007, 412, 865, 824, 774, 736, 347, 302, 559, 313, 1039, 991, 663, 419, 864, 418, 70, 805, 144, 319, 69, 916, 1053, 978, 143, 211, 301, 361, 379, 432, 538, 700, 637, 592, 145, 1218, 509, 877, 669, 278, 355, 360, 325, 776, 398, 40, 980, 456, 745, 584, 1145, 1062, 321, 194, 561, 497, 693, 543, 975, 906, 822, 931, 454, 295, 296, 437, 495, 434, 624, 742, 424, 873, 802, 972, 223, 270, 425, 461, 48, 753, 966, 974, 125, 786, 953, 524, 777, 500, 548, 380, 507, 914, 610, 130, 755, 433, 297, 377, 1119, 383, 698, 730, 531, 1031, 602, 763, 492, 695, 511, 1064, 525, 781, 760, 904, 526, 896, 964, 898, 157, 806, 1154, 467, 191, 1003, 833, 872, 416, 431, 891, 557, 729, 233, 887, 923, 965, 562, 816, 997, 959, 122, 158, 343, 726, 546, 749, 782, 728, 1011, 480, 992, 665, 905, 599, 928, 581, 696, 541, 236, 421, 756, 917, 91],
dropping: 567 variantswhich have mutations at those sites.
/home/jgallowa/mambaforge/envs/multidms-dev/lib/python3.11/multiprocessing/popen_fork.py:66: RuntimeWarning: os.fork() was called. os.fork() is incompatible with multithreaded code, and JAX is multithreaded, so this will likely lead to a deadlock.
self.pid = os.fork()
invalid non-identical-sites: [212, 371, 375, 417, 452, 477, 484, 493, 498, 981], dropping 475 variants
Converting mutations for Delta-2
is reference, skipping
Converting mutations for Omicron_BA1-2
/home/jgallowa/mambaforge/envs/multidms-dev/lib/python3.11/multiprocessing/popen_fork.py:66: RuntimeWarning: os.fork() was called. os.fork() is incompatible with multithreaded code, and JAX is multithreaded, so this will likely lead to a deadlock.
self.pid = os.fork()
Let’s take a look at a few attributes now available through the data object.
Data.site_map gives us the wildtype sequence inferred from each observed substitutions observed in the data separately for each condition.
[6]:
data.site_map.head()
[6]:
| Delta-2 | Omicron_BA1-2 | |
|---|---|---|
| 1 | M | M |
| 2 | F | F |
| 3 | V | V |
| 4 | F | F |
| 5 | L | L |
While the site map above gives the entire wildtype for each condition, we can easily view the sites for which a given condition wildtype differs from that of the reference via Data.non_identical_sites.
[7]:
data.non_identical_sites['Omicron_BA1-2'].head()
[7]:
| Delta-2 | Omicron_BA1-2 | |
|---|---|---|
| 19 | R | T |
| 67 | A | V |
| 95 | T | I |
| 156 | G | E |
| 339 | G | D |
The set of all mutations we are able to learn about with this model is defined by all mutations seen across all variants, for all condition groups combined. Mutations observed at non-identical sites on non-reference condition variants are converted to be with respect to the reference wildtype at that site, in other words they are treated, reported, and encoded in the binarymap as if the substitution had occurred on the reference background. To get a succinct tuple of all mutations seen in the
data, we can use Data.mutations attribute
[8]:
data.mutations[:5]
[8]:
('M1I', 'M1-', 'F2L', 'F2Y', 'V3F')
Perhaps more useful, multidms.Data.mutations_df gives more mutation-specific details, primarily the number of variant backgrounds any given mutation has been seen on, for each condition.
[9]:
data.mutations_df.head()
[9]:
| mutation | wts | sites | muts | times_seen_Delta-2 | times_seen_Omicron_BA1-2 | |
|---|---|---|---|---|---|---|
| 0 | M1I | M | 1 | I | 0 | 1 |
| 1 | M1- | M | 1 | - | 1 | 0 |
| 2 | F2L | F | 2 | L | 1 | 1 |
| 3 | F2Y | F | 2 | Y | 1 | 0 |
| 4 | V3F | V | 3 | F | 1 | 4 |
Data.variants_df gives us all variants after the various data prepping options such as barcode aggregation, have been applied. See the API documentation for more.
[10]:
data.variants_df.head()
[10]:
| condition | aa_substitutions | weight | func_score | var_wrt_ref | |
|---|---|---|---|---|---|
| 0 | Delta-2 | 599 | -0.15963 | ||
| 1 | Delta-2 | A1016S | 1 | -1.29760 | A1016S |
| 2 | Delta-2 | A1016T | 1 | -0.88240 | A1016T |
| 3 | Delta-2 | A1016T K1191L | 1 | -0.03900 | A1016T K1191L |
| 4 | Delta-2 | A1020C | 1 | 0.50800 | A1020C |
The ‘weight’ column above gives the number of barcodes that were seen for a given variant before they and their respective functional scores were aggregated. The ‘var_wrt_ref’ columns shows the converted ‘aa_substitutions’ to be with respect to the reference as described above. Above, we just see a few reference variants, thus there is no conversion applied. Let’s look at a non-reference condition variant with a non-identical site mutation.
[11]:
data.variants_df.query("condition == 'Omicron_BA1-2' and aa_substitutions.str.contains('212')").head()
[11]:
| condition | aa_substitutions | weight | func_score | var_wrt_ref | |
|---|---|---|---|---|---|
| 6545 | Omicron_BA1-2 | Q23L I285F W633R W1212L | 1 | -3.5000 | R19T A67V T95I G156E G339D S373P N440K G446S G... |
| 6831 | Omicron_BA1-2 | S162I W1212L | 1 | -2.1074 | R19T A67V T95I G156E G339D S373P N440K G446S G... |
In the conversion, we see all that the “bundle” of mutations which distinguish Omicron BA1 from Delta are now encoded as if they were simply mutations seen on a Delta background with some exceptions. Notice that the variant at index \(4116\) had a “I212A” mutation. That mutation is now encoded as “L212A”, which exemplifies a substitution that has been converted to be with respect to the reference wildtype, “L”, at site 212. Conversely, if the mutation at a non-identical site results in homology with the reference wildtype, then that site’s substitutions is left out completely from the conversion. For example, the variant at index \(4458\) contains the substitution “I212L”, but there is no 212 substitution observed in the respective conversion.
Model class¶
The Model object initializes and stores the model parameters determined by the mutations observed in the data, as well as the post-latent model specified. A full description of the options for models and the resulting object attributes are available via the API documentation, or directly from the python docstring directly via
help(multidms.Model)
Note:
Parameter initialization is a deterministic generation process in which starting values are sampled from a distribution using the jax.random module. You may optionally set a “seed” PRNG Key of your choosing, by default the Key is 0.
Next, we’ll create the default model by simply passing the Data object created above.
[12]:
model = multidms.Model(data)
[13]:
print(model)
Model
Name: unnamed
Data: unnamed
Converged: False
So far, we have not fit the parameters to the data. The most flexible option for fitting to the data is to use the Model.fit method directly, like so:
[14]:
model.fit(maxiter=5000)
/home/jgallowa/Projects/multidms/multidms/model.py:1181: RuntimeWarning: Model training error did not reach the tolerance threshold. Final error: 0.021850742189881294, tolerance: 0.0001
warnings.warn(
This method uses the jaxopt.ProximalGradient optimizer to fit the parameters (in place) to the data. Note that later we’ll introduce the model_collection module interface for a more streamlined approach to creating and fitting one or more Model objects – but the attributes and methods of individual Model objects are still be quite useful.
Note the warning about convergence. The default convergence threshold is set to \(10^{-4}\) which can sometimes take more playing with hyperparameters and more iterations to acheive. Toi suppress this warning, simply pass warn_unconverged=True. For our spike analysis manuscript, we needed to regularize model parameters and train the models for close to 30K iterations before convergence at this tolerence was acheived.
Model.convergence_trajectory_df gives the models error metric (as reported by jaxopt state object – and is useful to see how the model is changing through the fitting process) as well as the loss on the training data.
[15]:
import seaborn as sns
fig, ax = plt.subplots(2, 1, figsize=(10, 5))
for i, m in enumerate(["loss", "error"]):
sns.lineplot(
model.convergence_trajectory_df,
x="step",
y=m,
ax=ax[i],
# yscale="log",
)
ax[i].set_yscale("log")
plt.tight_layout()
plt.show()
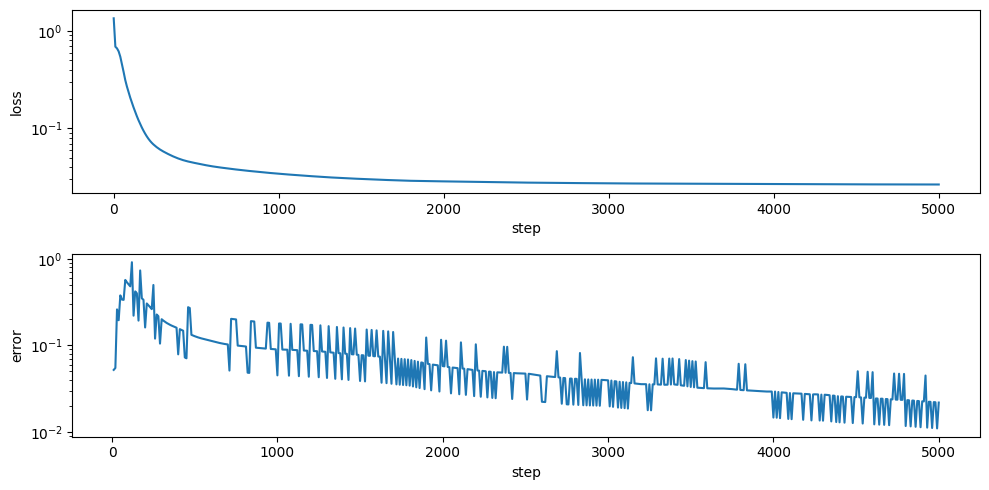
Here, we can see the model did not converge, but the model loss seems to be roughly unchanged at this point and is good enough for the purposes of this example.
The Model object allows provides many of the same properties, like mutations and variants dataframes, but add additional features relevant to the parameters of this model. Model.get_mutations_df returns the associated data object’s mutations_df as seen above, along with the \(\beta\) and \(S_{m,h}\) parameter’s associated with each mutation.
[16]:
help(multidms.Model.get_mutations_df)
Help on _lru_cache_wrapper in module multidms.model:
get_mutations_df(self, times_seen_threshold=0, phenotype_as_effect=True, return_split=True)
Mutation attributes and phenotypic effects
based on the current state of the model.
Parameters
----------
times_seen_threshold : int, optional
Only report mutations that have been seen at least
this many times in each condition. Defaults to 0.
phenotype_as_effect : bool, optional
if True, phenotypes are reported as the difference
from the conditional wildtype prediction. Otherwise,
report the unmodified model prediction.
return_split : bool, optional
If True, return the split mutations as separate columns:
'wts', 'sites', and 'muts'.
Defaults to True.
Returns
-------
pandas.DataFrame
A copy of the mutations data, `self.data.mutations_df`,
with the mutations column set as the index, and columns
with the mutational attributes (e.g. betas, shifts) and
conditional functional score effect (e.g. ) added.
The columns are ordered as follows:
- beta_a, beta_b, ... : the latent effect of the mutation
- shift_b, shift_c, ... : the conditional shift of the mutation
- predicted_func_score_a, predicted_func_score_b, ... : the
predicted functional score of the mutation.
[17]:
model.get_mutations_df(phenotype_as_effect=False).head()
[17]:
| wts | sites | muts | times_seen_Delta-2 | times_seen_Omicron_BA1-2 | beta_Delta-2 | beta_Omicron_BA1-2 | shift_Omicron_BA1-2 | predicted_func_score_Delta-2 | predicted_func_score_Omicron_BA1-2 | |
|---|---|---|---|---|---|---|---|---|---|---|
| mutation | ||||||||||
| M1I | M | 1 | I | 0 | 1 | -0.670376 | -0.670376 | 0.000000 | -1.924031 | -2.092655 |
| M1- | M | 1 | - | 1 | 0 | -1.210833 | -1.217279 | -0.006446 | -3.518891 | -3.696349 |
| F2L | F | 2 | L | 1 | 1 | 0.376333 | 0.376333 | 0.000000 | 0.886560 | 0.760452 |
| F2Y | F | 2 | Y | 1 | 0 | 0.624053 | 0.624053 | 0.000000 | 1.397594 | 1.287470 |
| V3F | V | 3 | F | 1 | 4 | 0.061322 | -0.366089 | -0.427411 | 0.137714 | -1.191158 |
Similarly, Model.get_variants_df now provides the latent (\(z\)) and functional score (\(\hat{y}_{v, h}\)) predictions as well as gamma-corrected functional score (\(y'_{v, h}\)). See the Biophysical documentation for more. Note that for the reference condition, \(\gamma_{h}\) is always equal to \(0\), and thus the functional score is always equal to the gamma corrected functional scores for these variants.
[18]:
help(multidms.Model.get_variants_df)
Help on _lru_cache_wrapper in module multidms.model:
get_variants_df(self, phenotype_as_effect=True)
Training data with model predictions for latent,
and functional score phenotypes.
Parameters
----------
phenotype_as_effect : bool
if True, phenotypes (both latent, and func_score)
are calculated as the _difference_ between predicted
phenotype of a given variant and the respective experimental
wildtype prediction. Otherwise, report the unmodified
model prediction.
Returns
-------
pandas.DataFrame
A copy of the training data, `self.data.variants_df`,
with the phenotypes added. Phenotypes are predicted
based on the current state of the model.
[19]:
model.get_variants_df().head()
[19]:
| condition | aa_substitutions | weight | func_score | var_wrt_ref | predicted_latent | predicted_func_score | |
|---|---|---|---|---|---|---|---|
| 0 | Delta-2 | 599 | -0.15963 | 0.000000 | -3.712308e-16 | ||
| 1 | Delta-2 | A1016S | 1 | -1.29760 | A1016S | -0.456546 | -1.270584e+00 |
| 2 | Delta-2 | A1016T | 1 | -0.88240 | A1016T | -0.213680 | -5.759269e-01 |
| 3 | Delta-2 | A1016T K1191L | 1 | -0.03900 | A1016T K1191L | -0.126598 | -3.365835e-01 |
| 4 | Delta-2 | A1020C | 1 | 0.50800 | A1020C | 0.261282 | 6.454972e-01 |
[20]:
print(model.state)
ProxGradState(iter_num=Array(5000, dtype=int64, weak_type=True), stepsize=Array(0.5, dtype=float64), error=Array(0.02185074, dtype=float64), aux=None, velocity={'beta': {'Delta-2': Array([-0.67035874, -1.21096323, 0.37641966, ..., -0.63904707,
0.09749028, 0.60156794], dtype=float64), 'Omicron_BA1-2': Array([-0.67035874, -1.21740883, 0.37641966, ..., 0.32806356,
-0.56374356, 0.60156794], dtype=float64)}, 'beta0': {'Delta-2': Array([0.75801103], dtype=float64), 'Omicron_BA1-2': Array([0.70161721], dtype=float64)}, 'shift': {'Delta-2': Array([0., 0., 0., ..., 0., 0., 0.], dtype=float64), 'Omicron_BA1-2': Array([ 0. , -0.00644561, 0. , ..., 0.96711063,
-0.66123384, 0. ], dtype=float64)}, 'theta': {'ge_bias': Array([-8.17273411], dtype=float64), 'ge_scale': Array([11.973], dtype=float64)}}, t=Array(2502.95282886, dtype=float64, weak_type=True))
One other particularly useful method for making predictions on held-out validation, or testing data is Model.add_phenotypes_to_df. See
help(Model.add_phenotypes_to_df)
for details on this method.
In addition to the functions above which return raw DataFrames, there exists a few useful plotting methods for the Model object. Each plotting method will either populate a provided matplotlib.axes object provided, or generate it’s own. For a full description of the plotting methods please see the API documentation.
First, let’s take a look at the prediction accuracy on all training data as well as the global epistasis fit
[21]:
fig, ax = plt.subplots(1, 2, figsize=[8,4])
model.plot_epistasis(ax=ax[1], alpha=0.15, show=False, legend=True)
model.plot_pred_accuracy(ax=ax[0], alpha=0.15, show=False, legend=False)
ax[1].set_title("Global epistasis fit")
ax[0].set_title("Training set accuracy")
plt.show()
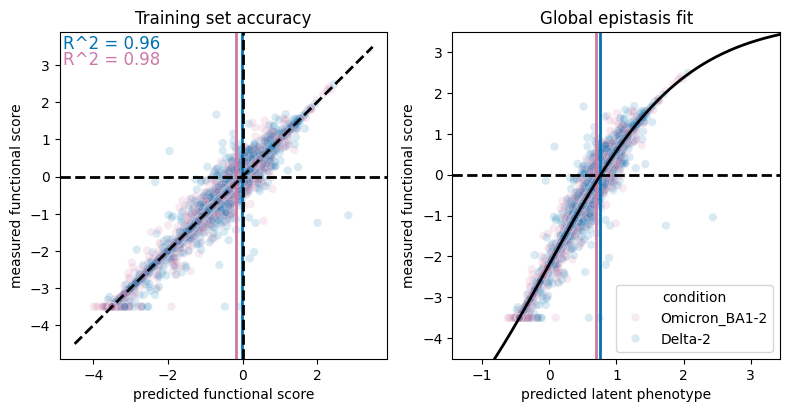
[22]:
model.params
[22]:
{'shift': {'Delta-2': array([0., 0., 0., ..., 0., 0., 0.]),
'Omicron_BA1-2': array([ 0. , -0.00644573, 0. , ..., 0.96713367,
-0.66127992, -0. ])},
'theta': {'ge_bias': Array([-8.17271859], dtype=float64),
'ge_scale': Array([11.973], dtype=float64)},
'beta': {'Delta-2': Array([-0.67037649, -1.21083294, 0.37633261, ..., -0.63905219,
0.09754517, 0.60171278], dtype=float64),
'Omicron_BA1-2': Array([-0.67037649, -1.21727867, 0.37633261, ..., 0.32808149,
-0.56373475, 0.60171278], dtype=float64)},
'beta0': {'Delta-2': Array([0.75802565], dtype=float64),
'Omicron_BA1-2': Array([-1.15687509], dtype=float64)}}
[23]:
model.get_variants_df(phenotype_as_effect=False).head()
[23]:
| condition | aa_substitutions | weight | func_score | var_wrt_ref | predicted_latent | predicted_func_score | |
|---|---|---|---|---|---|---|---|
| 0 | Delta-2 | 599 | -0.15963 | 0.758026 | -0.020004 | ||
| 1 | Delta-2 | A1016S | 1 | -1.29760 | A1016S | 0.301480 | -1.290588 |
| 2 | Delta-2 | A1016T | 1 | -0.88240 | A1016T | 0.544346 | -0.595931 |
| 3 | Delta-2 | A1016T K1191L | 1 | -0.03900 | A1016T K1191L | 0.631427 | -0.356588 |
| 4 | Delta-2 | A1020C | 1 | 0.50800 | A1020C | 1.019307 | 0.625493 |
We can also take a quick look at the distribution of any parameter set in the model. Below we’ll take a look at the distribution of shift parameters for the non reference BA1 condition. The distribution, by default, splits the shifts associated with stop codon mutations as a sanity check for the model fit. We expect stop codons to be equally deleterious no matter which condition they occur in, and thus, they should primarily be zero.
[24]:
fig, ax = plt.subplots(figsize=[8,4])
agg_func = lambda x: onp.abs(onp.mean(onp.sum(x)))
model.plot_param_hist("shift_Omicron_BA1-2", ax=ax, show=False)
ax.set_yscale("log")
ax.legend()
ax.set_ylabel("log value")
ax.set_title("Shift parameter value distribution")
plt.show()
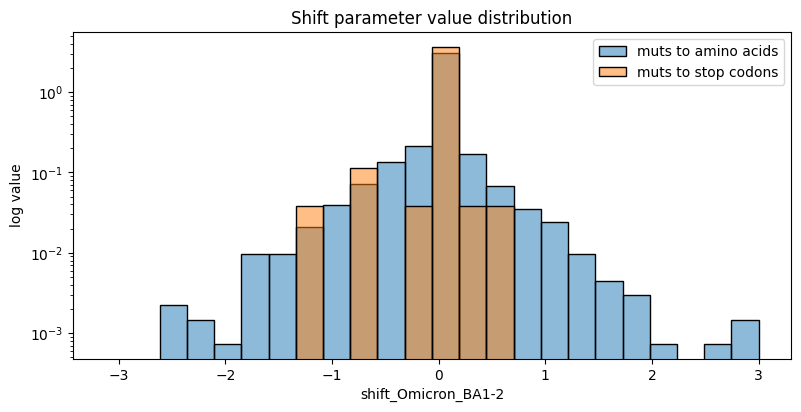
Perhaps the best way to explore parameter values associated with individual mutations, is Model.mut_shift_plot() which offers the ability to interactively visualize a model’s beta (\(\beta_m\)), experimental shift (\(\Delta_{d,m}\)), and phenotype predictions (\(\hat{y}_{m, d}\)). The plot is interactive, and allows you to hover over a mutation to see the associated values. The plot also allows you to zoom in on a region of interest using the site zoom bar.
[25]:
model.mut_param_heatmap(mut_param="beta")
[25]:
Note that the reference experimental wildtype’s are marked with an ‘x’, below we visualize the shift parameters associated with the non-reference experiment. You’ll note that at site where the two experiment wildtypes differ, we mark the non-reference wildtype with a colored ‘o’.
[26]:
model.mut_param_heatmap(mut_param="shift")
[26]:
[27]:
model.mut_param_heatmap(mut_param="predicted_func_score")
[27]:
Finally, we can save the tuned model via pickle (be sure to note the multidms version before dumping - Here be dragons).
[28]:
import pickle
pickle.dump(model, open(f"example_model_{multidms.__version__}.pkl","wb"))
fit_model & fit_models utilities¶
In the previous example notebook, we saw an explanation of the Data and Model class for fitting, and visualizing the results from a single model. Here, we will see how to use the ModelCollection class and associated utilities to fit multiple models (in parallel using multiprocessing) for aggregation and comparison of the results between fits.
Two very common use cases for this interface include:
Shrinkage analysis of lasso coefficient values
Training on distinct replicate training datasets
To give an example of each below, we use the multidms.fit_models function to get a collection of fits (in the form of a pandas.DataFrame object) spanning two replicate datasets, and a range of lasso coefficient values. We then instantiate a multidms.ModelCollection object from these fits to aggregate and visualize the results from the fits.
Note
This module functionally wraps the Model interface for convenience. If you’re training on cpu’s and have more than one core in your machine then this is definitely way to go. Currently, the code doesn’t do anything clever to optimize GPU usage by many models training in parallel. If you wanted to use a pipeline to farm out the fitting processes independently, the same DataFrame could be acquired by collecting the individual Series objects returned by fit_one_model, then
concatenated using the simple multidms.model_collection.stack_fit_models utility function - all of which are demonstrated below.
In the previous example, we showed data from two conditions, and fit a single model to the data. Here, we’ll load multiple replicates of that same data from three deep mutational scanning experiments across Delta, Omicron BA.1, and BA.2 Spike protein.
[33]:
func_score_df = (
pd.read_csv("docs_func_score_df_delta_BA1_BA2.csv")
.fillna("")
.replace({"Omicron_BA.1" : "Omicron_BA1", "Omicron_BA.2" : "Omicron_BA2"})
)
func_score_df
[33]:
| func_score | aa_substitutions | condition | replicate | n_subs | |
|---|---|---|---|---|---|
| 0 | -0.5087 | L24V F486L D820E | Delta | 1 | 3 |
| 1 | -0.1940 | N1125K | Delta | 1 | 1 |
| 2 | 0.9906 | V16I D138C F456Y T678S E990D | Delta | 1 | 5 |
| 3 | -0.6554 | G75S T76I M731I L1004F | Delta | 1 | 4 |
| 4 | -3.5000 | L176S L229P K558R S975Y T998S | Delta | 1 | 5 |
| ... | ... | ... | ... | ... | ... |
| 432316 | -0.7932 | G614K Q762E Q1071R | Omicron_BA2 | 2 | 3 |
| 432317 | -0.3706 | D339T | Omicron_BA2 | 2 | 1 |
| 432318 | -0.6116 | I358L T1006I T1066S T1077A | Omicron_BA2 | 2 | 4 |
| 432319 | -0.4363 | S408R R765L K1073E | Omicron_BA2 | 2 | 3 |
| 432320 | -3.5000 | S98A A570M D1163Y S1252C | Omicron_BA2 | 2 | 4 |
432321 rows × 5 columns
[34]:
func_score_df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 432321 entries, 0 to 432320
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 func_score 432321 non-null float64
1 aa_substitutions 432321 non-null object
2 condition 432321 non-null object
3 replicate 432321 non-null int64
4 n_subs 432321 non-null int64
dtypes: float64(1), int64(2), object(2)
memory usage: 16.5+ MB
[35]:
func_score_df.condition.unique()
[35]:
array(['Delta', 'Omicron_BA1', 'Omicron_BA2'], dtype=object)
We would like to create two replicate training datasets, each of which should consist of one replicate from each of the three experiments. For simplicity, we’ll group the three experiments deriving from replicate ‘1’ together, and similarly for replicate ‘2’ – keeping in mind there is no significance to the replicate names in this case.
We’ll create the Data objects, as we’ve done before, but this time we’ll create independent Data objects for each replicate. Keep in mind that when comparing across replicate datasets using the multidms.ModelCollection interface, it is best to keep the reference, and non-reference conditions consistent among datasets.
[36]:
data_replicates = {
rep: multidms.Data(
func_score_df.query("replicate == @rep"),
alphabet = multidms.AAS_WITHSTOP_WITHGAP,
collapse_identical_variants = "mean",
reference = "Delta",
verbose = False,
nb_workers=4,
name = f"Replicate {rep}"
)
for rep in [1, 2]
}
from pprint import pprint
pprint(data_replicates)
/home/jgallowa/mambaforge/envs/multidms-dev/lib/python3.11/multiprocessing/popen_fork.py:66: RuntimeWarning: os.fork() was called. os.fork() is incompatible with multithreaded code, and JAX is multithreaded, so this will likely lead to a deadlock.
self.pid = os.fork()
/home/jgallowa/mambaforge/envs/multidms-dev/lib/python3.11/multiprocessing/popen_fork.py:66: RuntimeWarning: os.fork() was called. os.fork() is incompatible with multithreaded code, and JAX is multithreaded, so this will likely lead to a deadlock.
self.pid = os.fork()
/home/jgallowa/mambaforge/envs/multidms-dev/lib/python3.11/multiprocessing/popen_fork.py:66: RuntimeWarning: os.fork() was called. os.fork() is incompatible with multithreaded code, and JAX is multithreaded, so this will likely lead to a deadlock.
self.pid = os.fork()
/home/jgallowa/mambaforge/envs/multidms-dev/lib/python3.11/multiprocessing/popen_fork.py:66: RuntimeWarning: os.fork() was called. os.fork() is incompatible with multithreaded code, and JAX is multithreaded, so this will likely lead to a deadlock.
self.pid = os.fork()
/home/jgallowa/mambaforge/envs/multidms-dev/lib/python3.11/multiprocessing/popen_fork.py:66: RuntimeWarning: os.fork() was called. os.fork() is incompatible with multithreaded code, and JAX is multithreaded, so this will likely lead to a deadlock.
self.pid = os.fork()
/home/jgallowa/mambaforge/envs/multidms-dev/lib/python3.11/multiprocessing/popen_fork.py:66: RuntimeWarning: os.fork() was called. os.fork() is incompatible with multithreaded code, and JAX is multithreaded, so this will likely lead to a deadlock.
self.pid = os.fork()
/home/jgallowa/mambaforge/envs/multidms-dev/lib/python3.11/multiprocessing/popen_fork.py:66: RuntimeWarning: os.fork() was called. os.fork() is incompatible with multithreaded code, and JAX is multithreaded, so this will likely lead to a deadlock.
self.pid = os.fork()
/home/jgallowa/mambaforge/envs/multidms-dev/lib/python3.11/multiprocessing/popen_fork.py:66: RuntimeWarning: os.fork() was called. os.fork() is incompatible with multithreaded code, and JAX is multithreaded, so this will likely lead to a deadlock.
self.pid = os.fork()
{1: Data, 2: Data}
The model_collection module offers a simple interface to create and fit Model objects. First, Let’s fit a single model to one of the Data replicates above. To do this, we’ll simply need to define the model parameters.
[37]:
single_set_of_params = {
"dataset": data_replicates[1], # only one replicate dataset
"num_training_steps" : 1,
"iterations_per_step": 15000, # Small number of iterations for purposes of this example
"alpha_d" : True,
"scale_coeff_ridge_alpha_d": 1e-3,
"scale_coeff_lasso_shift": 1e-5,
}
For a full list and descriptions of available hyperparameters, see:
help(multidms.model_collection.fit_one_model)
With these, we can now fit a singular model
[38]:
fit = multidms.model_collection.fit_one_model(**single_set_of_params)
fit
[38]:
epistatic_model Sigmoid
output_activation Identity
init_theta_scale 6.5
init_theta_bias -3.5
n_hidden_units 5
lower_bound None
PRNGKey 0
num_training_steps 1
iterations_per_step 15000
alpha_d True
scale_coeff_ridge_alpha_d 0.001
scale_coeff_lasso_shift 0.00001
dataset_name Replicate 1
model Model\nName: unnamed\nData: Replicate 1\nConve...
fit_time 88
dtype: object
Now we have the Model object along with the associated hyperparameters that were fit the model to the replicate dataset. Let’s take a look at the shifts’s (\(\Delta_{m, d}\)) from this fit using the Model.mut_param_heatmap method.
[39]:
fit.model.mut_param_heatmap(mut_param="shift")
[39]:
Currently, the model_collection interface offers two public functions: fit_one_model, as we saw above, and fit_models. The former is wrapped by the latter, and allows for multiple models to be fit in parallel by spawning child processes using multiprocessing. The fit_models function takes in a single dictionary which defines the parameter space of all models you wish to run. Each value in the dictionary must be a list of values, even in the case of singletons. This function
will compute all combinations of the parameter space and pass each combination to multidms.utils.fit_wrapper to be run in parallel, thus only key-value pairs which match the fit_one_model kwargs are allowed.
To exemplify this, let’s again define the hyperparameters, but this time, we’ll specify each value as a list of values to be fit in parallel.
[45]:
collection_params = {
"dataset": list(data_replicates.values()),
"maxiter": [1000],
"output_activation" : ["Softplus"],
"lower_bound" : [-3.5],
"scale_coeff_ridge_beta" : [1e-6],
"scale_coeff_ridge_ge_scale": [1e-3],
"scale_coeff_lasso_shift": [0.0, 1e-6, 1e-5, 5e-5, 1e-4, 1e-3],
}
Before we fit the models, let’s take a look at what collection of models we’re specifying with this dictionary by calling upon a “private” function multidms.model_collection._explode_params_dict. As implied by the “private” this functionality behavior is hidden from the user and is performed intrinsically when calling fit_models.
[47]:
from pprint import pprint
pprint(multidms.utils.explode_params_dict(collection_params)[:2])
[{'dataset': Data,
'lower_bound': -3.5,
'maxiter': 1000,
'output_activation': 'Softplus',
'scale_coeff_lasso_shift': 0.0,
'scale_coeff_ridge_beta': 1e-06,
'scale_coeff_ridge_ge_scale': 0.001},
{'dataset': Data,
'lower_bound': -3.5,
'maxiter': 1000,
'output_activation': 'Softplus',
'scale_coeff_lasso_shift': 1e-06,
'scale_coeff_ridge_beta': 1e-06,
'scale_coeff_ridge_ge_scale': 0.001}]
What is produced is a list of **kwargs to pass to fit_one_model. In this case there are 12 total models to fit (2 replicate datasets x 6 lasso strengths). To fit these models, we simply pass the collection_params to fit_models and specify the number of threads available to run the model fits in parallel.
[49]:
n_fit, n_failed, fit_models = multidms.model_collection.fit_models(collection_params, n_threads=12)
The third object returned by fit_models is a pandas.DataFrame object which contains the results from each model fit by stacking the pd.Series objects as returned by fit_one_model.
[50]:
fit_models
[50]:
| epistatic_model | output_activation | init_theta_scale | init_theta_bias | n_hidden_units | lower_bound | PRNGKey | maxiter | scale_coeff_lasso_shift | scale_coeff_ridge_beta | scale_coeff_ridge_ge_scale | dataset_name | model | fit_time | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Sigmoid | Softplus | 6.5 | -3.5 | 5 | -3.5 | 0 | 1000 | 0.0 | 0.000001 | 0.001 | Replicate 1 | Model\nName: unnamed\nData: Replicate 1\nConve... | 109 |
| 1 | Sigmoid | Softplus | 6.5 | -3.5 | 5 | -3.5 | 0 | 1000 | 0.000001 | 0.000001 | 0.001 | Replicate 1 | Model\nName: unnamed\nData: Replicate 1\nConve... | 108 |
| 2 | Sigmoid | Softplus | 6.5 | -3.5 | 5 | -3.5 | 0 | 1000 | 0.00001 | 0.000001 | 0.001 | Replicate 1 | Model\nName: unnamed\nData: Replicate 1\nConve... | 108 |
| 3 | Sigmoid | Softplus | 6.5 | -3.5 | 5 | -3.5 | 0 | 1000 | 0.00005 | 0.000001 | 0.001 | Replicate 1 | Model\nName: unnamed\nData: Replicate 1\nConve... | 108 |
| 4 | Sigmoid | Softplus | 6.5 | -3.5 | 5 | -3.5 | 0 | 1000 | 0.0001 | 0.000001 | 0.001 | Replicate 1 | Model\nName: unnamed\nData: Replicate 1\nConve... | 109 |
| 5 | Sigmoid | Softplus | 6.5 | -3.5 | 5 | -3.5 | 0 | 1000 | 0.001 | 0.000001 | 0.001 | Replicate 1 | Model\nName: unnamed\nData: Replicate 1\nConve... | 107 |
| 6 | Sigmoid | Softplus | 6.5 | -3.5 | 5 | -3.5 | 0 | 1000 | 0.0 | 0.000001 | 0.001 | Replicate 2 | Model\nName: unnamed\nData: Replicate 2\nConve... | 106 |
| 7 | Sigmoid | Softplus | 6.5 | -3.5 | 5 | -3.5 | 0 | 1000 | 0.000001 | 0.000001 | 0.001 | Replicate 2 | Model\nName: unnamed\nData: Replicate 2\nConve... | 105 |
| 8 | Sigmoid | Softplus | 6.5 | -3.5 | 5 | -3.5 | 0 | 1000 | 0.00001 | 0.000001 | 0.001 | Replicate 2 | Model\nName: unnamed\nData: Replicate 2\nConve... | 105 |
| 9 | Sigmoid | Softplus | 6.5 | -3.5 | 5 | -3.5 | 0 | 1000 | 0.00005 | 0.000001 | 0.001 | Replicate 2 | Model\nName: unnamed\nData: Replicate 2\nConve... | 107 |
| 10 | Sigmoid | Softplus | 6.5 | -3.5 | 5 | -3.5 | 0 | 1000 | 0.0001 | 0.000001 | 0.001 | Replicate 2 | Model\nName: unnamed\nData: Replicate 2\nConve... | 106 |
| 11 | Sigmoid | Softplus | 6.5 | -3.5 | 5 | -3.5 | 0 | 1000 | 0.001 | 0.000001 | 0.001 | Replicate 2 | Model\nName: unnamed\nData: Replicate 2\nConve... | 106 |
This DataFrame is all that’s necessary to create a multidms.ModelCollection object.
ModelCollection class¶
The dataframe returned by fit_models can be used to instantiate a ModelCollection object, which in turn allows for a simple interface for getting raw aggregated mutational data, and to visualize these data from the collection of fits.
[51]:
mc = multidms.ModelCollection(fit_models)
To get the aggregated, raw mutational data in a nice tidy format, ModelCollection.split_apply_combine_muts has a straightforward name for a simple goal. This function follows the split-apply-combine paradigm to the collection of individual mutational effects tables (our example currently has 6) while keeping the fit hyperparameters of interest, tied to the data.
[52]:
combined_lasso_strengths = mc.split_apply_combine_muts(groupby=("dataset_name", "scale_coeff_lasso_shift"))
combined_lasso_strengths.head()
cache miss - this could take a moment
[52]:
| mutation | times_seen_Delta | times_seen_Omicron_BA1 | times_seen_Omicron_BA2 | beta_Delta | beta_Omicron_BA1 | shift_Omicron_BA1 | beta_Omicron_BA2 | shift_Omicron_BA2 | predicted_func_score_Delta | predicted_func_score_Omicron_BA1 | predicted_func_score_Omicron_BA2 | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| dataset_name | scale_coeff_lasso_shift | ||||||||||||
| Replicate 1 | 0.0 | A1015D | 5.0 | 2.0 | 3.0 | -1.199526 | -1.955241 | -0.755714 | -0.851112 | 0.348414 | -1.554889 | -2.520092 | -1.083576 |
| 0.0 | A1015Q | 0.0 | 8.0 | 0.0 | -0.048907 | -2.681171 | -2.632264 | -0.000320 | 0.048587 | -0.053516 | -3.140728 | -0.000353 | |
| 0.0 | A1015S | 8.0 | 22.0 | 29.0 | 0.179238 | -0.256491 | -0.435729 | -0.196018 | -0.375256 | 0.185579 | -0.303580 | -0.225457 | |
| 0.0 | A1015T | 7.0 | 12.0 | 22.0 | -1.782984 | -1.990034 | -0.207050 | -1.834713 | -0.051728 | -2.318638 | -2.557530 | -2.383881 | |
| 0.0 | A1015V | 0.0 | 6.0 | 7.0 | -0.080035 | -2.431665 | -2.351630 | -1.975145 | -1.895110 | -0.088201 | -2.972883 | -2.542748 |
The fit collection groupby features (“scale_coeff_lasso_shift”, and “dataset_name” in this case, and by default) are set as a multiindex – the index then easily distinguishes fit groups from from mutation features, and is more memory efficient. Also note that by default, only mutations shared by all datasets are returned, but this can be changed by setting inner_merge_dataset_muts=False.
While the raw data is nice for custom visualizations, the ModelCollection class offers a few plotting methods to quickly visualize the results from the collection of fits. In this example, we fit a collection of models across two replicate datasets, and a range of lasso coefficient values, but we may next wonder which of these strengths presents the best results? To answer this, let’s first take a look at the parameter correlation between replicate fits at each lasso coefficient value using
ModelCollection.mut_param_dataset_correlation.
[53]:
corr_df = mc.mut_param_dataset_correlation(times_seen_threshold=3, width_scalar=350, height=300)
corr_df
cache miss - this could take a moment
[53]:
Here, we can see that the shift (green and yellow in this case) parameter correlation increases with the strength of the lasso coefficient. At the highest value for the lasso coefficient, however, there is no correlation as the lasso penalty is so strong that all shift parameters are all driven to zero. This behavior exemplifies the sparsity (number of values equal to 0) of the parameters. To further investigate the sparsity, we can use ModelCollection.shift_sparsity to visualize the
sparsity of the shift parameters across the collection of fits.
[54]:
mc.shift_sparsity(times_seen_threshold=3)
[54]:
The sparsity chart groups the mutations types as either “nonsynonymous”, or “stop”. This is because we often use the stop sparsity as a gauge on the false-positive rate of the model. In other words, we expect that mutations to stop codons to be equally deleterious in all three homolog experiments, thus, the shifts for these mutations should be driven to zero before the nonsynonymous mutations, generally.
Given these two sets of results it seems like a reasonable penalty coefficient exists somewhere in the range (\(5e-05\), \(1e-04\)).
Just as you might use Model.mut_param_heatmap to visualize the mutation effects from a single model, you can use ModelCollection.mut_param_heatmap to visualize the aggregated mutation effects from a collection of models fit to multiple replicate datasets.
Using all defaults this would be called as follows:
heatmap_chart = mc.mut_param_heatmap()
However, our current example fit collection has 3 different lasso strengths, which don’t make sense to aggregate over. Thus, this call will result in:
ValueError: invalid query, more than one unique hyper-parameter besides dataset_name
To fix this, we must subset out model collection such that we are only aggregating across different training datasets.
[55]:
chart = mc.mut_param_heatmap(
times_seen_threshold=3,
query="scale_coeff_lasso_shift == 5e-5",
mut_param="shift"
)
chart
/home/jgallowa/Projects/multidms/multidms/model_collection.py:670: UserWarning: the fits that will be aggregated appear to differ by features other than dataset_name, this may result in unexpected behavior
warnings.warn(
cache miss - this could take a moment
[55]:
Of the results given above, it seems there’s a few notable shifts when looking at the aggregate of the replicates. In the case where you want to see the parameter value for a few mutations of interest across all fits, you can use ModelCollection.mut_param_traceplot function. Let take a look at the a few of the notable mutations from the heatmap above.
[56]:
mc.mut_param_traceplot(mutations = ["N542D", "D568N", "A846N", "N1173K"], mut_param="shift")
[56]: